NSF NCAR's Approach
Rigorous evaluation ensures AI advances our science with confidence and transparency.
What is Evaluation and Benchmarking?
Evaluation means testing how well AI models perform at their intended tasks. Comprehensive evaluation means systematically testing how well models perform across multiple dimensions, including physical consistency, scientific interpretability, and real-world applicability. This means verifying that AI outputs align with established physical laws and the scientific understanding of how the complex Earth system and its constituent parts interact, assessing performance across diverse conditions, including extremes, and evaluating how well models generalize beyond their training data to novel conditions.
Benchmarking means comparing different AI approaches against each other and against traditional (modeling) methods using standardized tests, frameworks, and datasets. This involves the use of well-characterized datasets and agreed-upon metrics. (See our AI-ready datasets here.)
Together, these approaches help us to understand what AI tools can reliably do, where they excel, and where they have limitations. This builds the evidential foundation we need for informed decisions about when and how to apply AI in Earth system science to enhance our capabilities.
Why Standard Testing Isn’t Enough
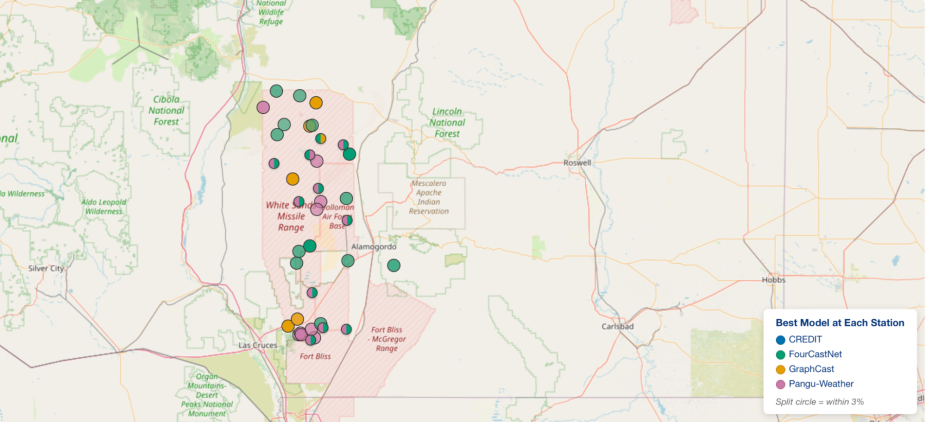
Figure: Compares the “Best Model at Each Station” between CREDIT, FourCastNet, GraphCast, and Pangu-Weather via a color coded circle. Where the models are within 3% of one another, the circle is split. From the BEACON AI Testbed.
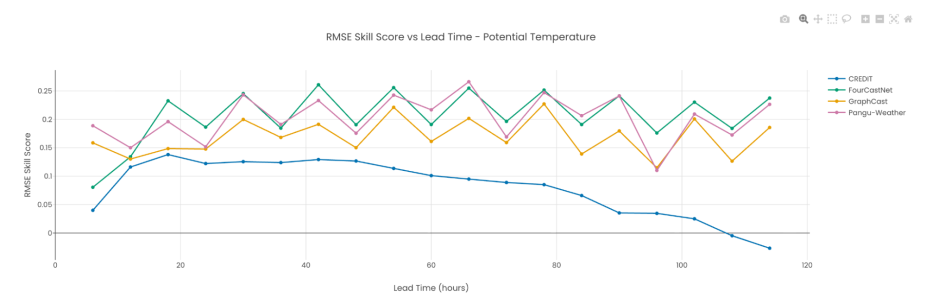
Traditional accuracy metrics, such as measuring average error, can be misleading in Earth system science. An AI weather model might show impressive empirical accuracy on available observations, but violate physical laws, predict “smoothed” forecasts rather than realistic weather patterns, or perform poorly during extreme events. NSF NCAR’s approach recognizes that for applications affecting people’s safety and decision-making, we need to test AI models across multiple dimensions, not just a single accuracy metric.
Why Evaluation and Benchmarking are a Priority
AI is transforming how we predict and understand the weather and the Earth-Sun system in all its complexity. The models and tools we develop are increasingly used in contexts that affect real decisions, i.e., where to evacuate before a hurricane, how to manage water during a drought, and where to allocate resources to establish long-term resilience to hazards. Rigorous evaluation ensures these tools work reliably across the full range of conditions they will encounter, not just in controlled testing environments. NSF NCAR’s commitment is that AI should enhance our scientific capabilities while maintaining the standards of physical consistency, transparency, and reliability expected of scientific experts.
NSF NCAR’s Multidimensional Approach
NSF NCAR evaluates AI models by asking several key questions:
- Does it follow physics? AI models should conserve mass, energy, and moisture, just like the real atmosphere and our physical models do.
- Does it capture realistic patterns? Models should reproduce the correct spatial and temporal structures and weather features.
- How confident should we be? Models should provide reliable uncertainty estimates that match their actual performance.
- Does it work in real conditions? Testing on non-training data (withheld data) is not enough. Models should perform in out-of-sample conditions to be considered reliable.