NSF NCAR's Priorities
How NSF NCAR Will Evaluate Comprehensive Evaluation and Benchmarking
Our benchmarking and evaluation research focus on demonstrating the reliability of AI systems:
- Reliability is about the model. It scrutinizes how well it performs, how consistently it behaves, and whether its outputs hold up under scrutiny.
- Trustworthiness is about the people using the model. It is about the judgment based on how credible a user finds a model for their particular situation.
You can find out more about our research on trust here. Below, we outline the core components of our comprehensive evaluation and benchmarking framework.
Multidimensional Assessment Frameworks
Develop evaluation approaches that go beyond single metrics to assess AI performance in terms of physical plausibility, scientific interpretability, out-of-sample skill, and consistency with established scientific knowledge. This includes creating protocols for testing AI models under diverse conditions and against multiple datasets, establishing standards for documenting model capabilities, and building evaluation workflows that can be applied systematically across different Earth system domains and models.
NSF NCAR sees a comprehensive evaluation of models and tools as key to responsible and reliable AI. Learn more about that pillar of our AI program here.
Explore our AI-ready datasets suitable for model benchmarking here.
Community Benchmarking and Intercomparison Infrastructure
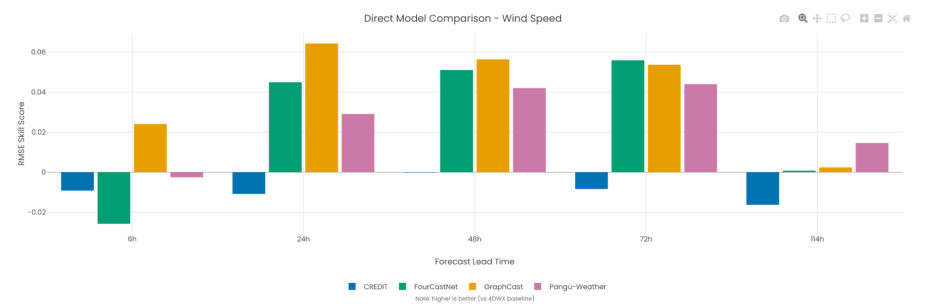
Establish well-characterized benchmark datasets and standardized evaluation protocols to enable fair comparisons between AI approaches and traditional methods. This includes curating high-quality evaluation datasets that represent diverse conditions and phenomena, developing common metrics appropriate to different Earth system applications, providing accessible platforms where researchers can test and compare approaches, and creating model intercomparison capabilities that enable different AI models to be evaluated against the same metrics and datasets for direct performance comparisons.
Learn more about our gold-standard model evaluation system, MetPlus, and how we are developing BEACON for AI models.
Model Intelligibility and Explainability
Build frameworks for understanding how AI models make predictions and what physical relationships they have learned. This includes developing explainable AI (XAI) techniques appropriate to Earth system applications, creating visualization tools that reveal model decision-making processes, establishing methods to verify that models learn physically meaningful patterns rather than spurious correlations, and providing interpretability assessments that help users understand model strengths, weaknesses, and appropriate applications.
Explore our current research on explainable AI and intelligibility.
Transparent Performance Communication
Create frameworks to clearly communicate AI model performance, including its strengths, limitations, and appropriate applications. This includes developing standardized reporting formats that capture the multidimensionality of performance characteristics, establishing guidelines for assessing uncertainty and reliability, creating model-readiness criteria that indicate whether AI tools are prepared for specific use cases or actionable uses, and ensuring that evaluation results are accessible to users with varying levels of expertise.
Continuous Improvement and Community Learning
Building systems to enable ongoing evaluation as new data becomes available and scientific understanding evolves. This includes creating mechanisms for community feedback on AI tool performance, establishing ways to update evaluations when models or datasets change, and fostering collaborative learning and development on open-source community platforms that drive sharing up-to-date knowledge on effective evaluation practices across the Earth system science community.