AI-Ready Data
All data hosted on NSF NCAR’s GDEX platform are accessible for AI and ML applications. In response to the growing demand for model training and evaluation datasets, NSF NCAR curates, standardizes, and publishes high-quality Earth system datasets optimized for AI-enabled research and discovery. AI-ready data refers to datasets stored in cloud-optimized formats (zarr or kerchunk) with standardized intake-ESM catalogs, designed so researchers can plug them directly into AI/ML workflows without extensive preprocessing.
Our AI-ready data holdings continue to expand as new observations, simulations, and community datasets are integrated.
Commonly used AI-Ready Datasets available on GDEX:
Reanalysis:
- CAM6 Data Assimilation Research Testbed (DART) Reanalysis: Cloud-Optimized Dataset
- ERA5 Reanalysis (0.25 Degree Latitude-Longitude Grid)
- ERA5 Reanalysis Model Level Data
- Japanese Reanalysis for Three Quarters of a Century (JRA-3Q)
- ERA5-Land hourly data from 1950 to present
Convective permitting models output:
- Multi-decadal Convection-permitting Simulation of Current Climate over South America using WRF
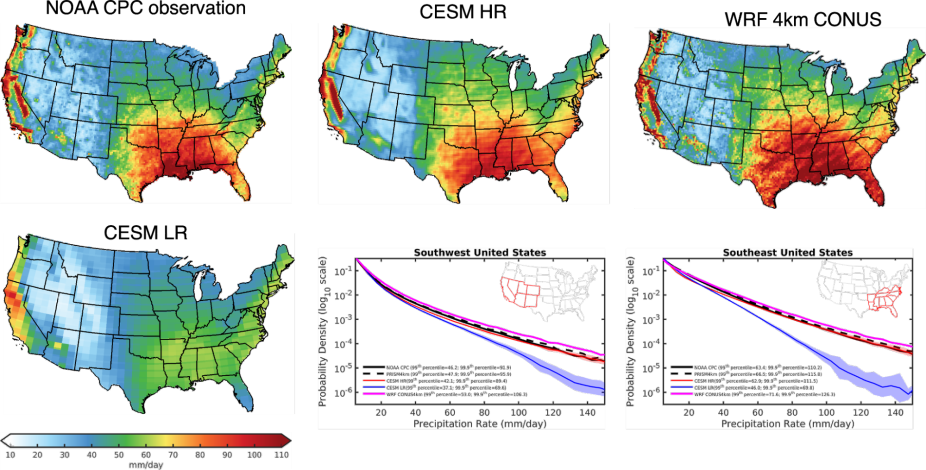
- Four-kilometer long-term regional hydroclimate reanalysis over the conterminous United States (CONUS)
CESM Output:
- Community Earth System Model v2 Large Ensemble (CESM2 LENS) Zarr Subset
- MESACLIP: Nominal 1-degree CESM (low-resolution) simulations corresponding to high-resolution experiments
CMIP Models Output:
ECMWF Forecasts:
Radar Data:
Regional models output:
- The Zarr store of NCAR NA-CORDEX Daily Data
- NA-CORDEX - North American component of the Coordinated Regional Downscaling Experiment
Other:
For general inquiries and data support questions, please contact the NSF NCAR Research Data Help Desk at datahelp@ucar.edu or through the NSF NCAR Geoscience Data Exchange Help Desk.